Knowledge Base Management
# Knowledge Base Management
——Learn about the methods and scenarios we provide for knowledge base management in this article.
# The Role of Knowledge Base Management
We hope that before you learn about the knowledge management feature, you understand its scenarios and uses:
● Usage scenario: Before using the AI Agent to converse with users, it is necessary to configure a knowledge base for the robot. When live chat, call center, or ticketing agent interacts with users, the knowledge base can also be used for intelligent replies.
● Purpose: To make AI Agents more professional and efficient in handling user chat.
# How to Use the Knowledge Base
The knowledge base is divided into two types: local knowledge base and webpage knowledge base.
● Local Knowledge Base: Directly create questions, articles, files in the Sobot knowledge base or import knowledge in bulk.
● Webpage Knowledge Base: Acquire knowledge through web crawling (requires activation of the AI Agent product).
The following will introduce you to how to use the local knowledge base:
# ● How to Create and Add Knowledge
On the [Knowledge Base Management] page, click the [Create] button to establish a local knowledge base.
Add categories to the knowledge base to meet specific business needs.
Add a knowledge base for classification tasks, supporting knowledge bases in the form of questions, articles, and files (Excel, PDF, TXT, DOCX).
a. File: Supports txt, pdf, docx, and excel formats. The content of uploaded files will be integrated into the RAG question-answering system for retrieval and generation. It is not recommended to upload product catalogs with extensive visual designs and color images, or PDFs converted from PPTs with unclear information structure and minimal text.
b. Article: Supports multiple rich text formats. For better Q&A results, we suggest prioritizing the article format when adding new knowledge. We also recommend that each article focus on solving one specific problem. For example, instead of writing an article covering multiple payment issues - such as payment, refunds, and shipping fees - write three separate articles, each describing one issue individually. Similarly, article knowledge will be integrated into the RAG Q&A system to participate in retrieval and generation.
c. Question: When the effect of a specific answer polished by a large model is not good, you can write a specific answer for it. This answer will not be polished by the large model. To improve the hit rate, you can add similar questions. For user questions, the system will first match through the NLP model, trying to find the standard question or similar questions. If the match is successful, the system will directly return the corresponding answer. This process does not require the participation of the large model, thus improving the response speed. If the NLP model does not match successfully, the question will be sent to the RAG question-answering system for deeper retrieval and generation.
In [More], support enabling, disabling, setting validity periods, and exporting functions for the knowledge base.
In [Add Knowledge], support uploading different language files.



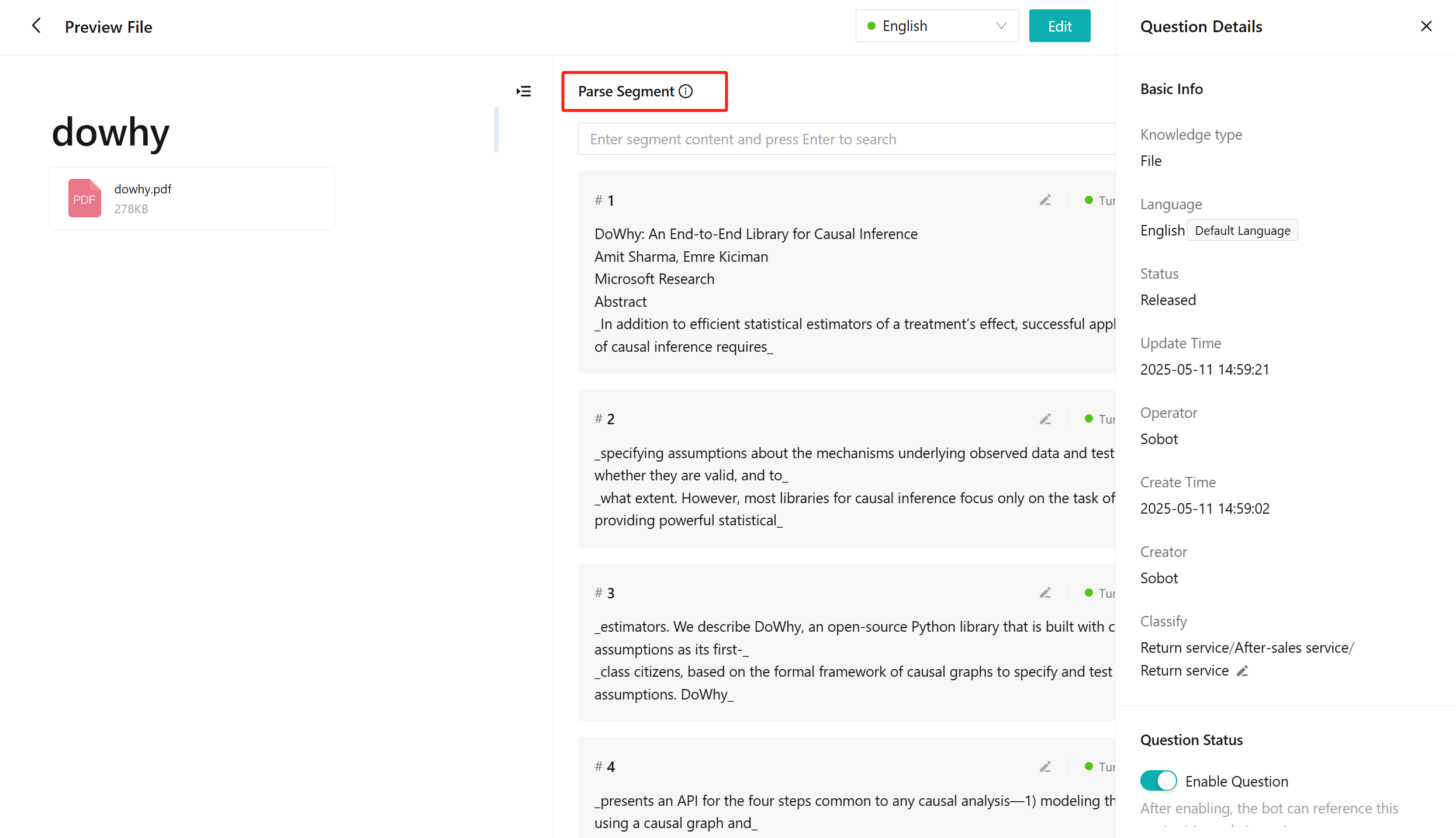
# ● Knowledge Parsing
Each document uploaded to the knowledge base will be parsed, segmented, and stored in a vectorized format. You can view the parsing results on the knowledge details page.
Parsing method: For ordinary documents, default text parsing is used; for some special PDF files, multi-modal parsing is performed:
a. Scanned PDF
b. The system detects that the garbled characters in the file exceed 5% or the image area in the PDF exceeds 60% of a single page area.
c. The average number of words per page in the PDF is less than 100, or the length of extractable characters on each randomly selected page is less than 100.
Chunking method: Annotate Markdown levels based on font size, then divide into different slices according to the different level identifiers of Markdown. When chunking, consider the number of characters in each slice. If the number of characters in a paragraph exceeds the threshold, it will be split into two segments.
a. English document: Block size threshold (thres_chunk) = 300 characters; Title length threshold (thres_title) = 30 characters.
b. Block size threshold = 500 characters, Title length threshold = 50 characters
Editing chunks: Segmenting documents significantly impacts the Q&A effectiveness in knowledge base applications. Before applying knowledge to robot Q&A, it is recommended to manually check the segmentation quality. Too short text segments lead to semantic loss; too long text segments introduce semantic noise that affects matching accuracy; obvious semantic truncation occurs when using maximum segment length limits, resulting in forced semantic breaks and missing content during recall.
Special Content Handling:
a. Table: Keep the table integrity. If it is too large, split it by row.
b. Q&A Pair: Keep the question and answer pairing intact.
c. Title: Identify and Mark Hierarchical Relationships.
d. Table of Contents: Identify and remove the table of contents section
e. Image: Move the image position to the end of the previous block.