Suggestion
# Suggestion
——This article will help you understand how to use the feature "Suggestion".
# The Role of Suggestion
We hope that before you learn about the role of Suggestion, you understand its scenarios and highlights:
● Usage scenario:
- KB Cold start. If your knowledge base is poorly maintained, you can use this function to learn historical human agent conversations, quickly improve the knowledge coverage of your KB.
2.Continuous operation stage. If your bot has a low independent reception rate, you can use this function to learn the agent conversations which bot can't handle independently.
● Highlights:
- Quickly generate knowledge based on historical conversations, allowing you to start using AI Agent in just a few minutes.
- Continuously generate missing knowledge based on recent conversations and automatically filter out knowledge with high similarity.
- Customize specific conditions such as specific agent or business types to control the conversation scope of the generated knowledge.
# How to Use Suggestion
The following will introduce you to the function and effect of each feature point:
# Configure from which sessions knowledge is generated
In [AI Agent - Operation - Suggestion], click on [Settings] to make the relevant Settings:
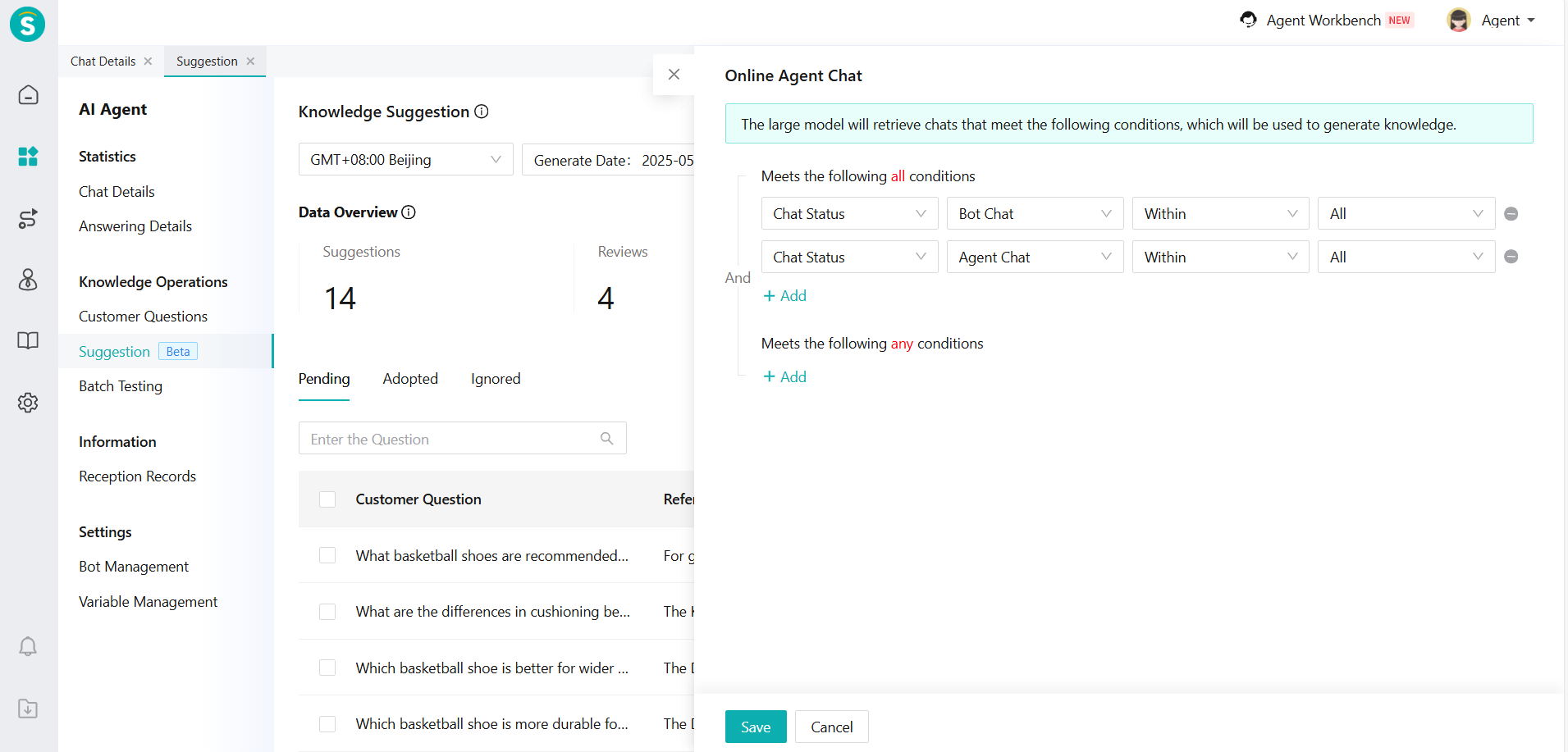
- Filter the conversation range: Click on [Live Chat] in [Knowledge Scope] to filter the conversation range. We suggest choosing a session where both bot and human agent are effective sessions.
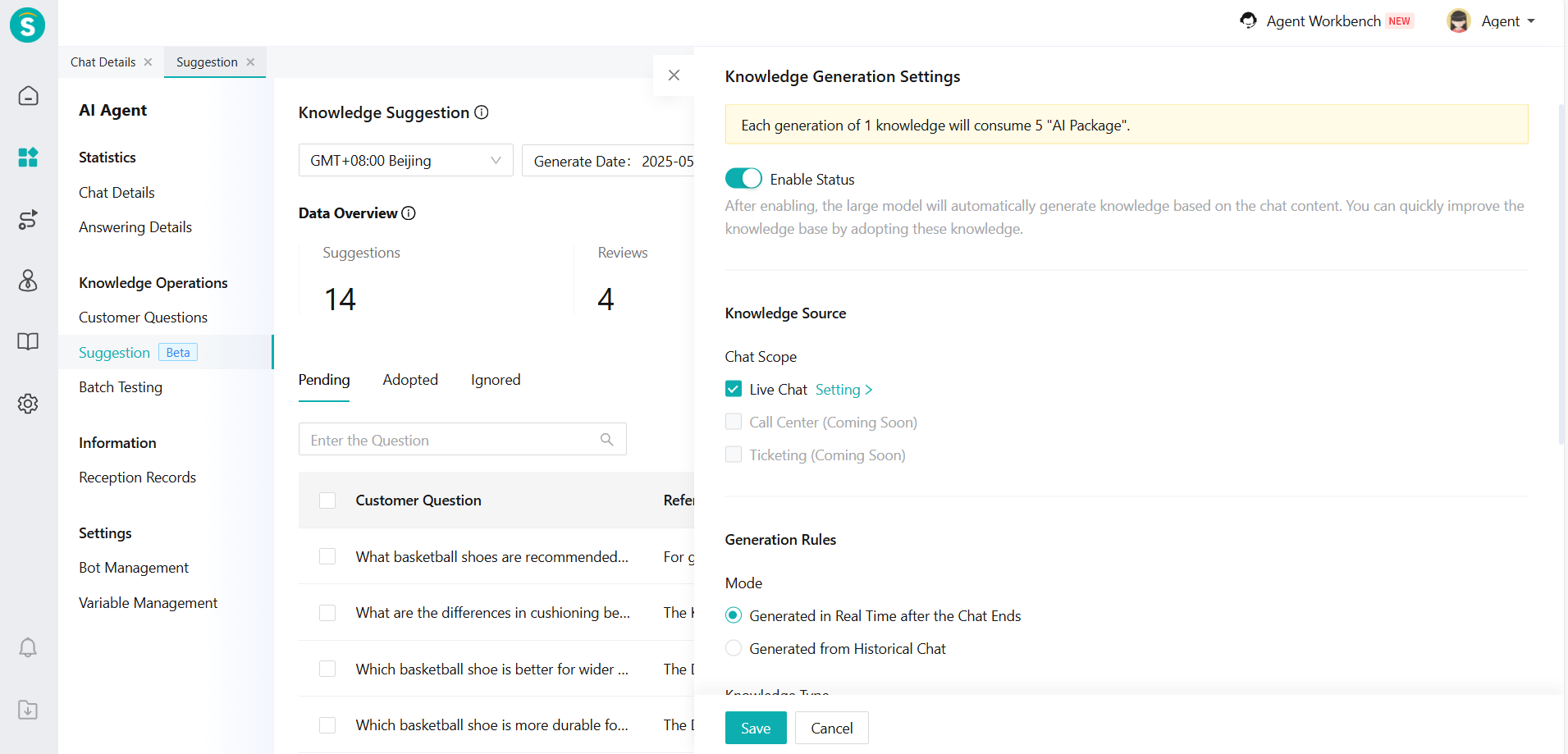
Figure 2: Settings Page 1
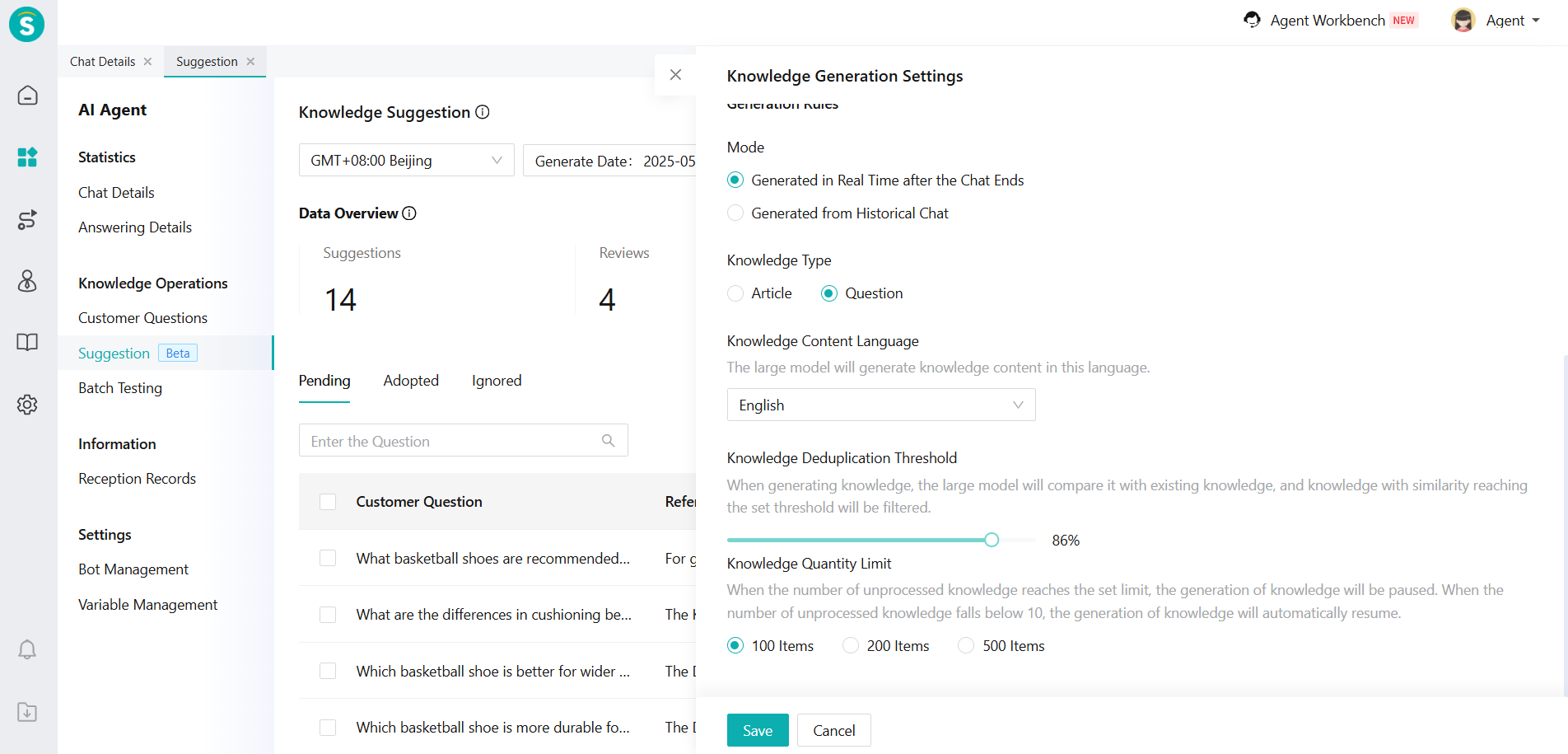
In the [Generation Rules], we can specify the mode of Suggestion - generating in real time after the chat ends or generated from historical chat.
The type of generated knowledge can be specified as an article or a question and multi-language Settings can be made.
Set a knowledge deduplication threshold: When encountering duplicate knowledge, AI will compare the generated knowledge with the existing knowledge. Knowledge whose similarity reaches the set threshold will be filtered out. The higher the threshold, the smaller the difference in the generated knowledg.
Knowledge quantity limit: When the number of unprocessed knowledge reaches the set number, the generation of knowledge will be suspended. When the number of unprocessed knowledge items is less than 10, knowledge generation will continue automatically.
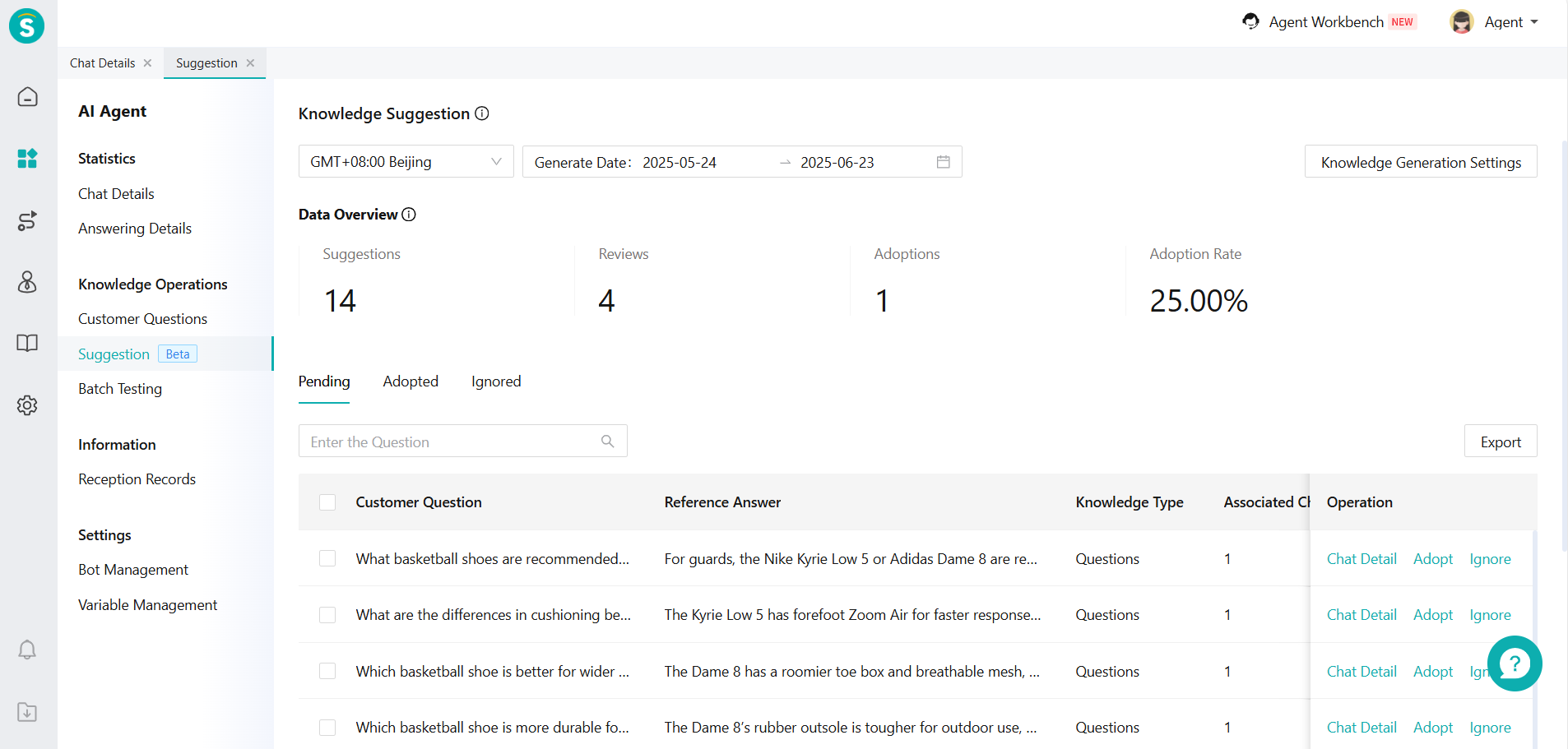
# ReView the Knowledge Suggestion
In the [Suggestion], your knowledge will be categorized into 3 categories: Pending, Adopted and Ignored.
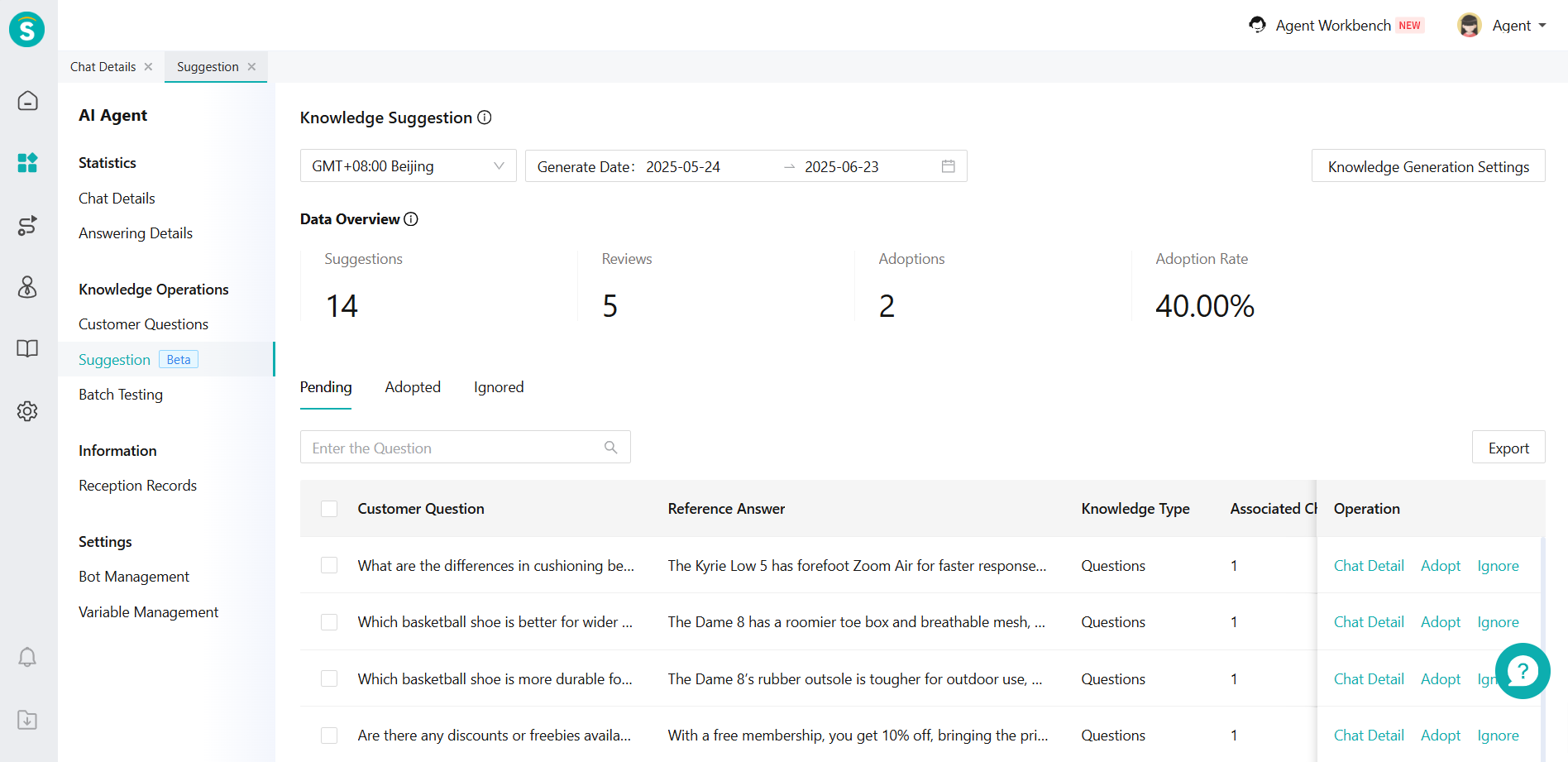
Specific indicators are listed below:
| Indicator | Explanation |
|---|---|
| Suggestions | The number of knowledge that the large model suggests through chat content. |
| Reviews | The number of suggested knowledge that the agent has adopted or ignored. |
| Adoptions | The number of suggested knowledge that the agent has adopted. |
| Adoption Rate | Adoption Rate = Adoptions / Reviews |
Click [Chat Detail] to open the Associated chat (Figure 6) and view all the chat related to the "Customer Question".
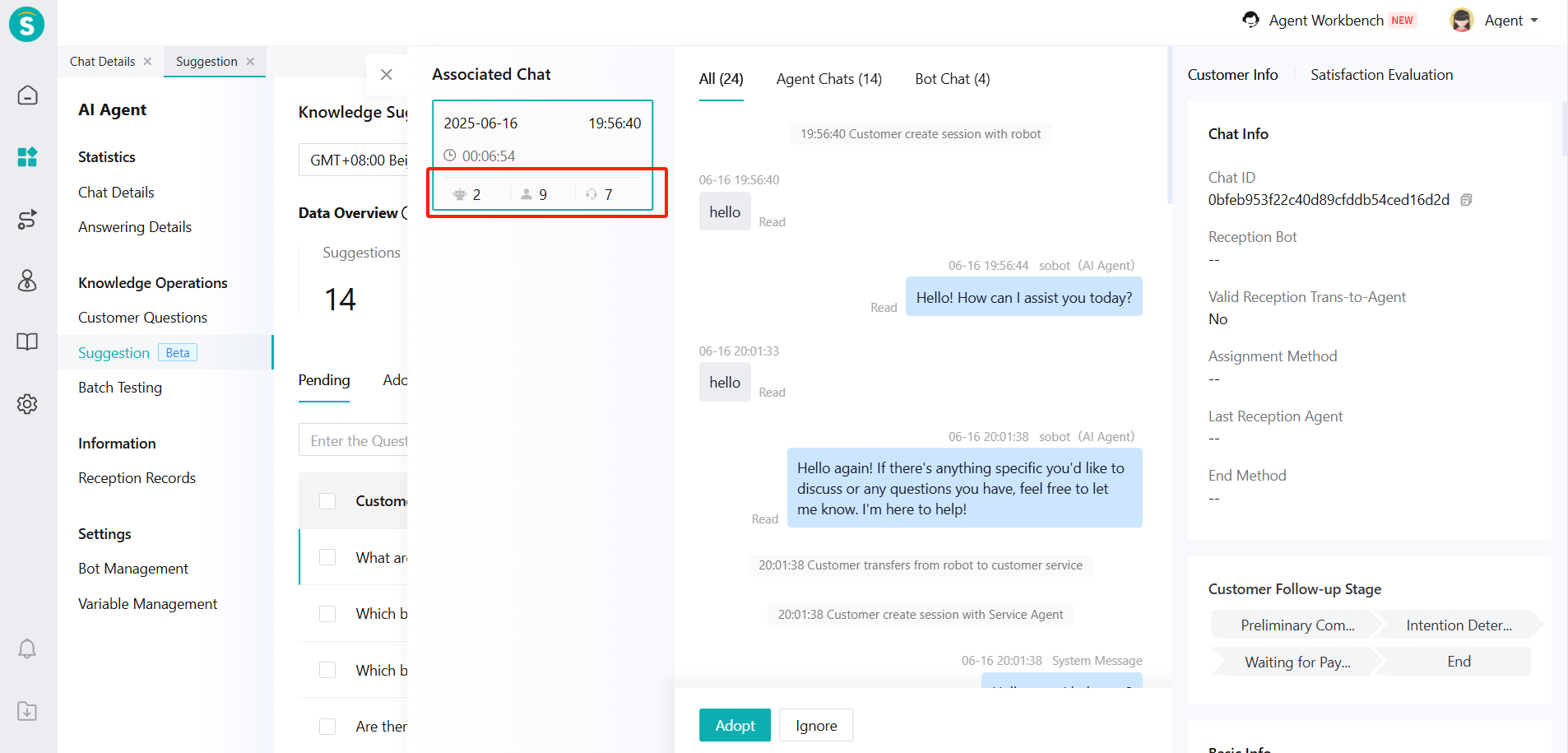
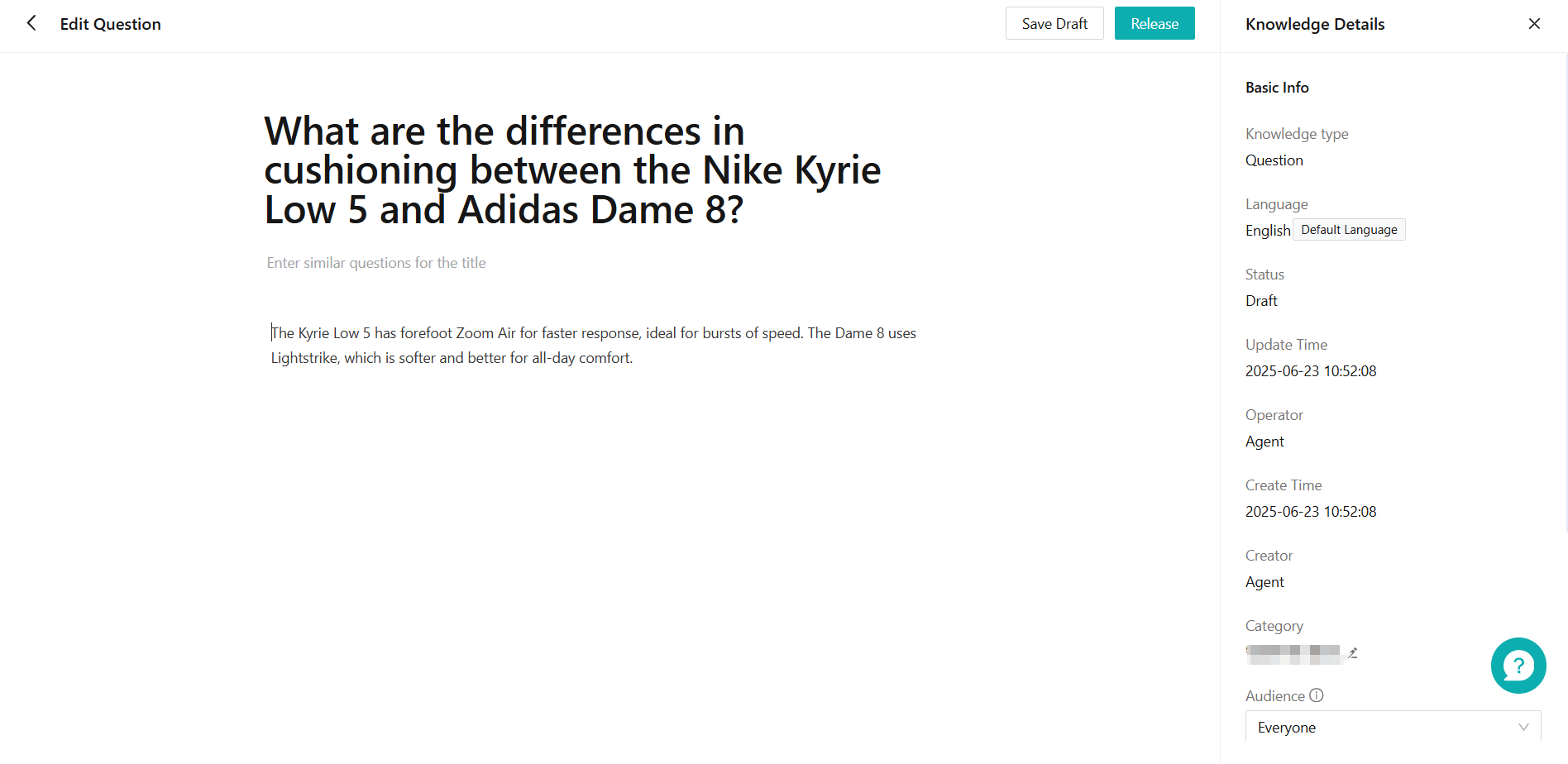
Figure 6: Associated chat page Click [Adopt], first, select which knowledge base and category to add to (Figure 7 page); then, go to the knowledge detail page (Figure 8 page) to edit the knowledge. After the knowledge is published, the published questions and answers will be displayed on the Adopted page (Figure 9).
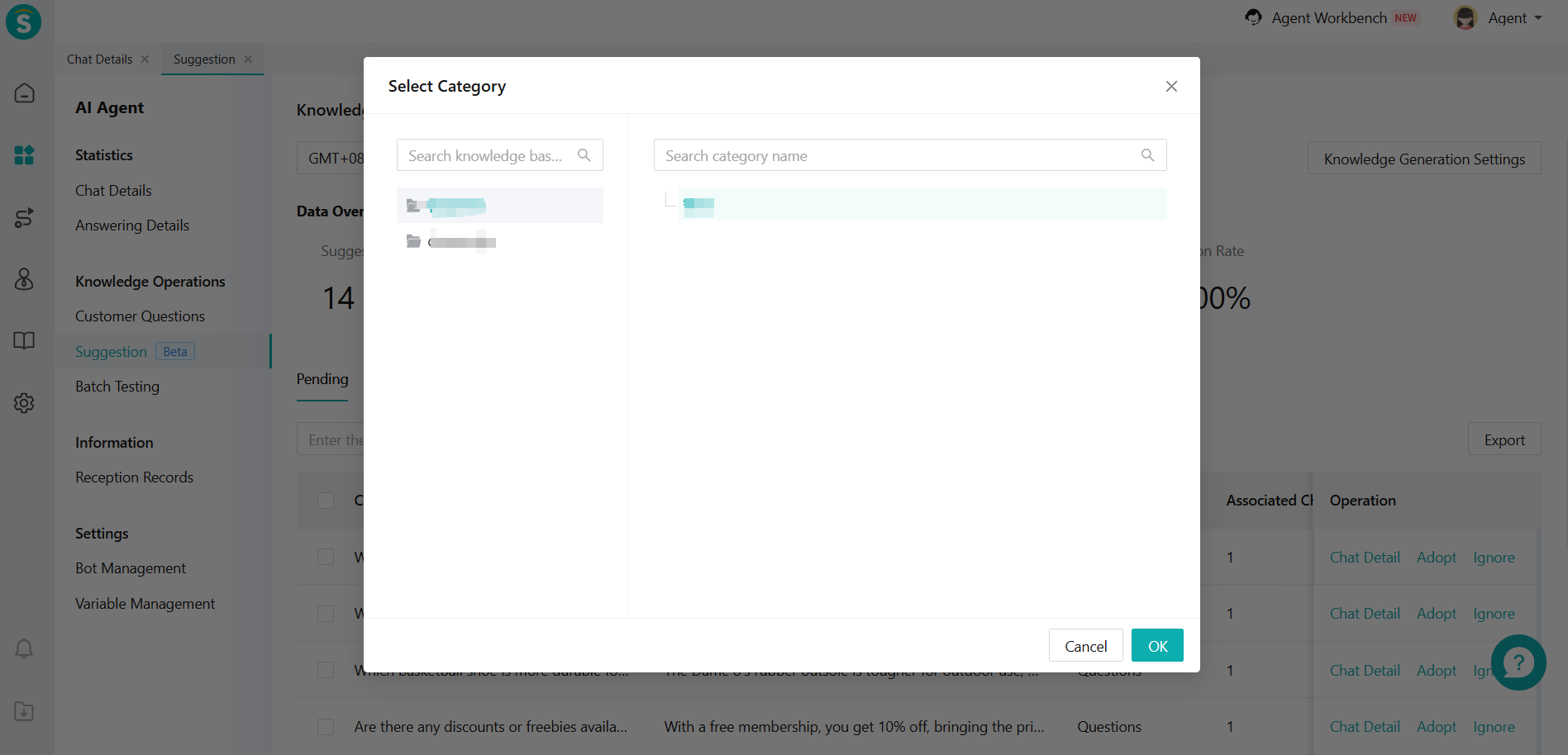
Figure 7: The page after clicking "Adopt"

- Click [Ignore], the generated questions and answers will be ignored (Figure 10).
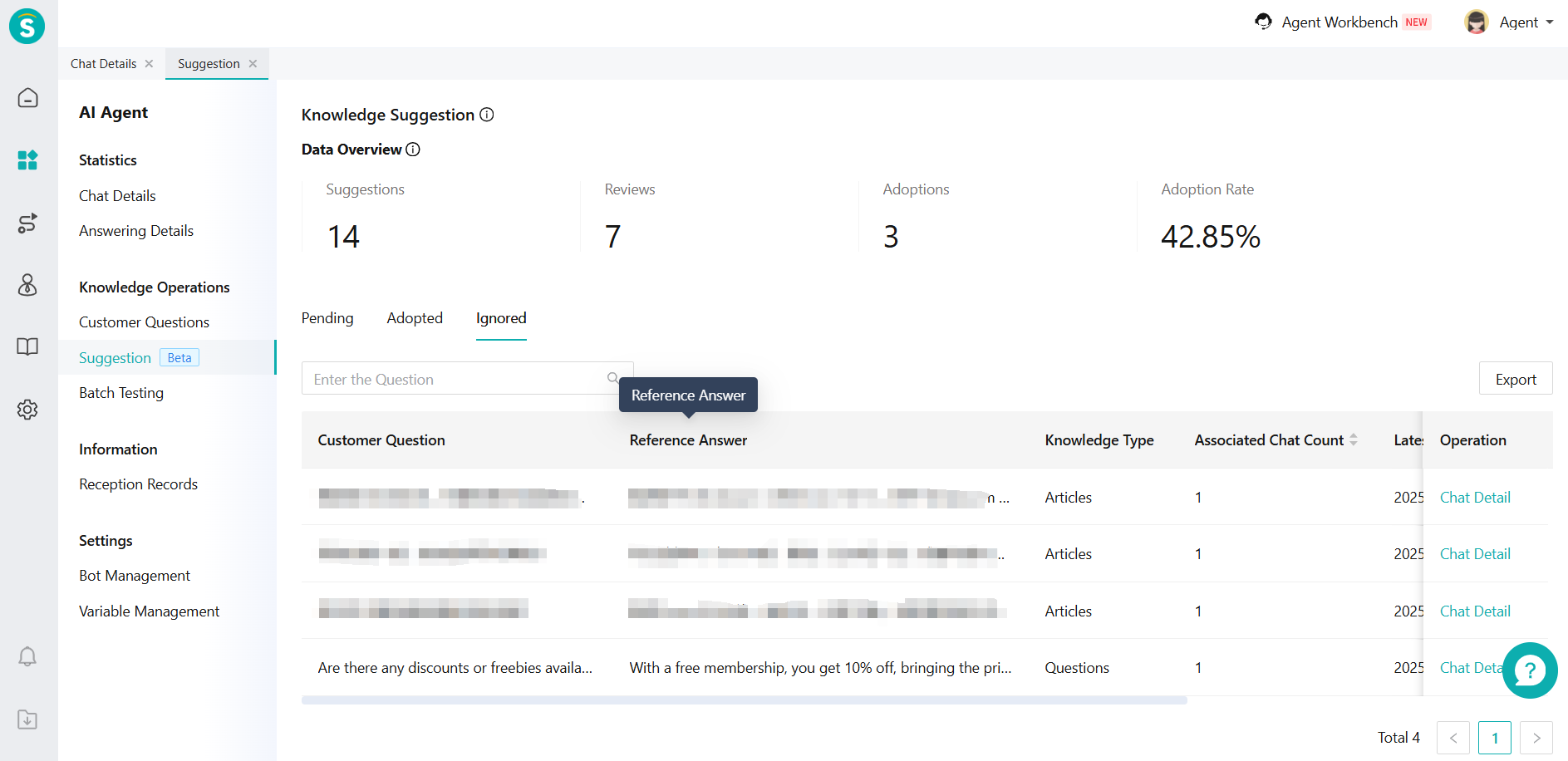
Figure 10: The knowledge has been ignored
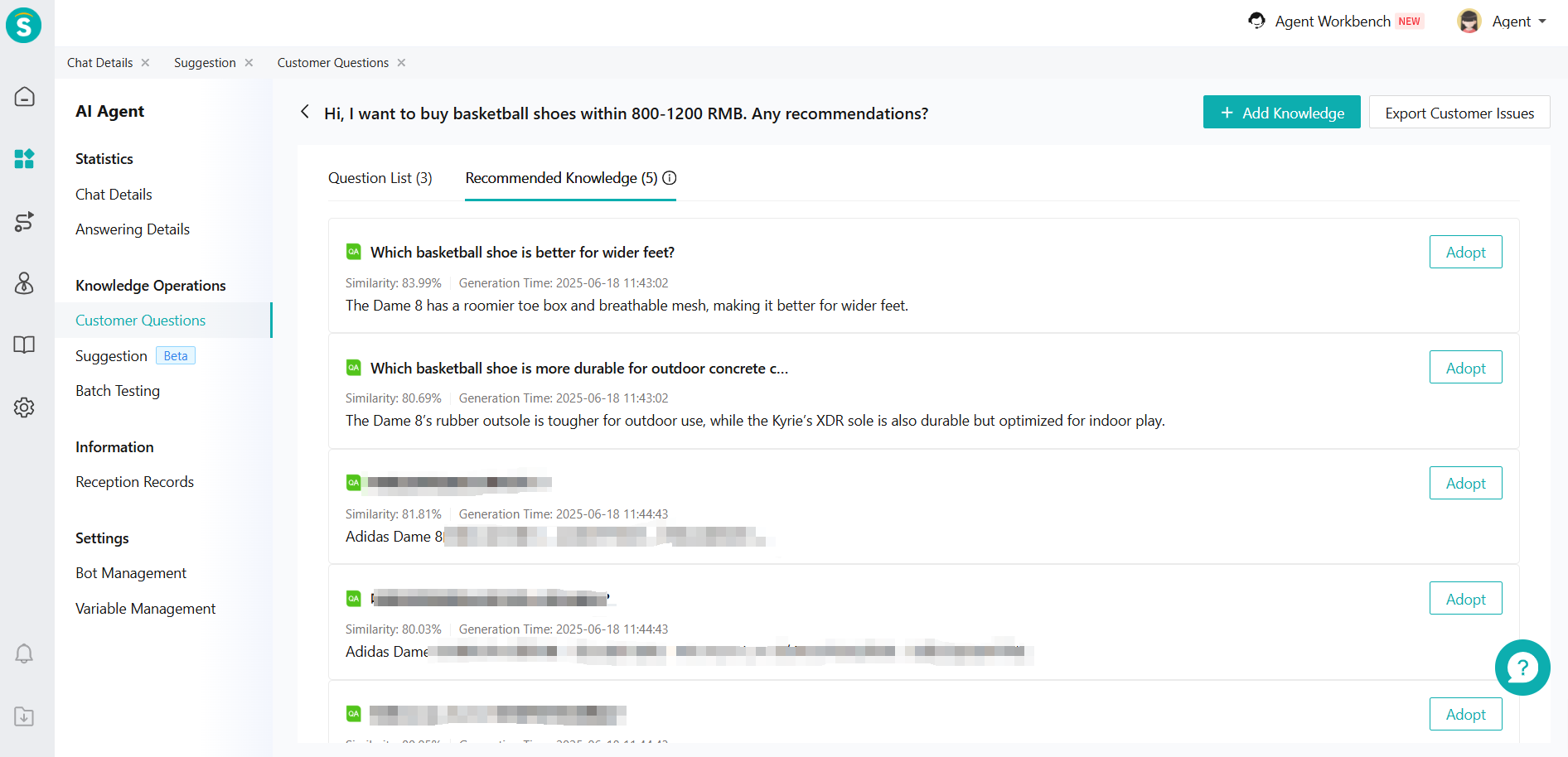
# Recommend the Knowledge from Suggestion
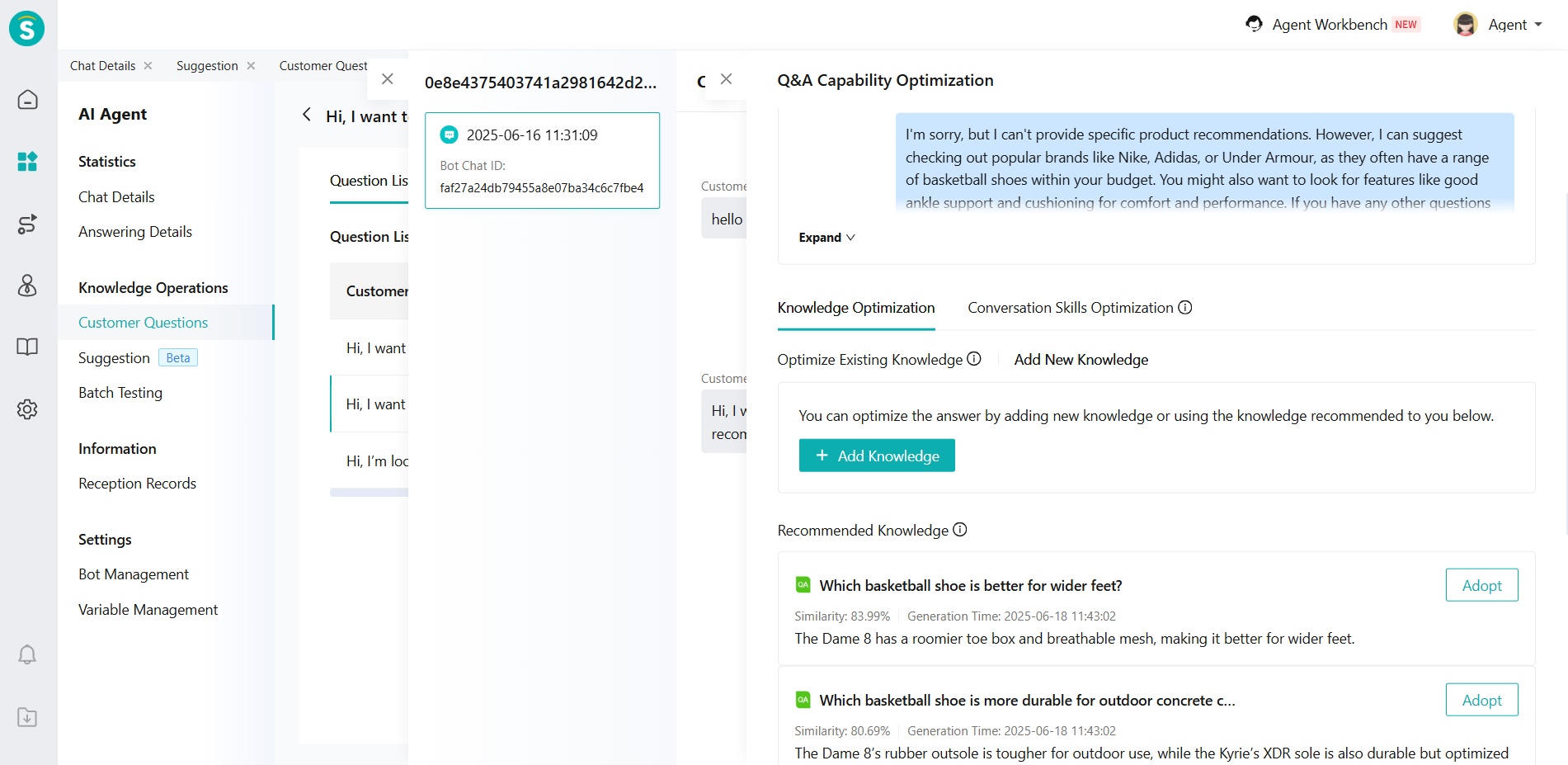
In [AI Agent-Knowledge Operations-Customer Question], AI will recommend you the similar knowledge of Suggestion in pending list. In addition, in the [Q&A Capability Optimization], AI will also recommend you the similar knowledge of Suggestion in pending list
# Billing method
In the Singapore and North American environments, 5 AI resource packages are consumed for each piece of knowledge generated. It should be noted that if a conversation has a large amount of content, multiple pieces of knowledge may be generated.
# Note: Special handling of generating knowledge
In order to generate knowledge that is more in line with business requirements, more effective, and more secure and compliant, Sobot has specially carried out the following processing:
# Filter the chat
Before generating knowledge from conversations using large models, we will conduct preliminary screening work using small-parameter models to quickly eliminate conversation content that does not meet the requirements. The specific screening criteria are as follows:
- Those needing manual intervention or offline processing, e.g., password reset requests.
- Containing personal privacy info like ID numbers, phone numbers, account balances, transaction records, or location data.
- With vague questions lacking key details, making it hard to grasp user intent.
- Involving short-time-limited answers that lose value over time, e.g., product shelf life.
- Having no valid info, such as mere greetings, closing remarks, or incomplete, interrupted topics.
- With rounds that are too short (insufficient info) or too long (mixed topics, redundancy).
# Knowledge deduplication
In actual business receptions, there may be a considerable number of similar conversations. To ensure that the suggestion is not repetitive, we will perform Knowledge deduplication to alleviate your knowledge operation pressure.
- We will filter out the suggestion that has a high repetition rate with the existing knowledge in the knowledge base based on the threshold for knowledge deduplication you set. This avoids your repeated adoption of existing knowledge.
- For the similar knowledge that has been generated, we will merge it and simultaneously tally the number of chat associated with it. For instance, if there are multiple chats in your business that all pertain to the issue of "account login abnormalities caused by network problems," ultimately, we will generate only one piece of knowledge suggestion and associate it with, as well as count, all the relevant sessions.